
Mohammad Javad Shafiee
mjshafiee at uwaterloo.ca
Co-founder & VP Research
DarwinAI, Canada
Adjunct Professor
University of Waterloo

mjshafiee at uwaterloo.ca
Co-founder & VP Research
DarwinAI, Canada
Adjunct Professor
University of Waterloo
Currently, his research team has been developing a new framework for designing automatic or semi-automatic deep learning models to improve modeling accuracy and performance in addition to speeding up the design process for different use cases.
Efficient, optimized and specialized machine learning models play an important role in real-world applications especially in the new edge AI era. Real-world applications and especially in the edge AI field are mostly restricted by hardware characteristics including computational power, available memory, and energy consumption; these constraints make the use cases of deep neural networks limited for several industries since it is very laborious to have a robust model and at the same time fulfill all operational requirements. This research focuses on developing advanced and novel frameworks to design graph-based machine learning models such as deep neural networks and graphical models with efficient computation, utilized in different industries such as autonomous driving cars, surveillance, and consumer electronics. In this research project we aim to bridge the gap between human and AI and augment the capability of human users by AI functionality to better design effective and efficient machine learning models.
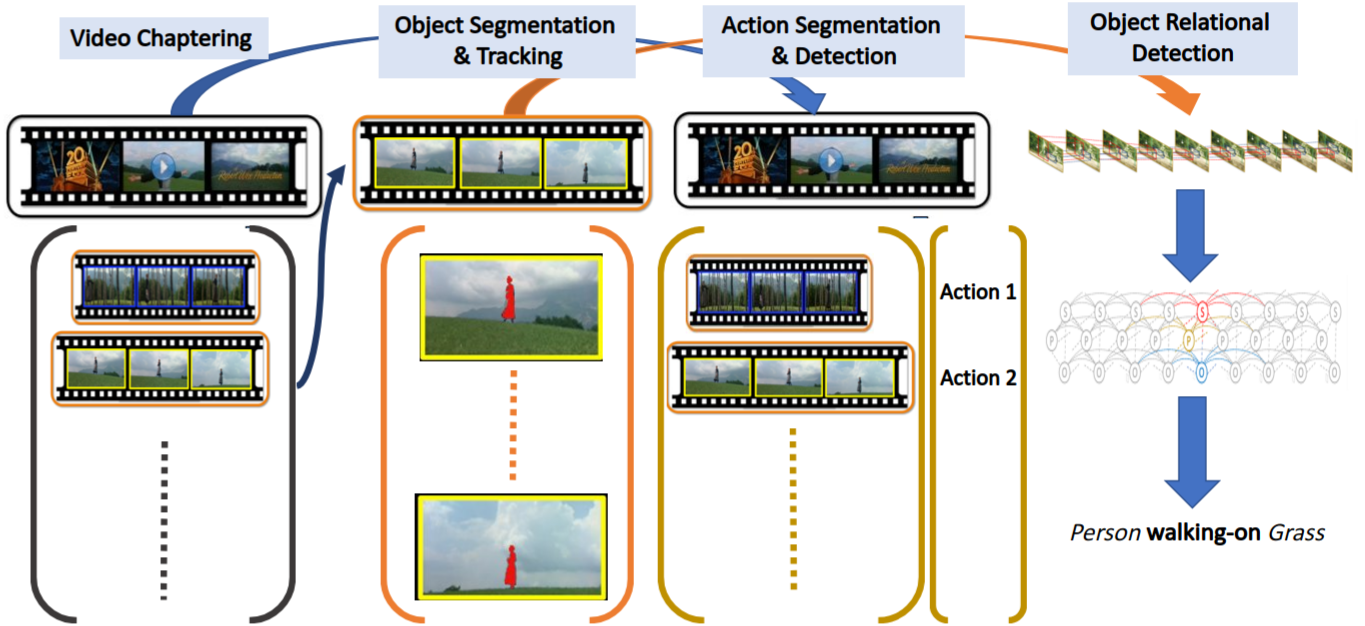
The analysis and extraction of meaningful information from video data is a vital application of machine learning, particularly given the explosion of video being produced, uploaded, transmitted, and stored worldwide. Machine learning and, more recently, deep learning methods have shown outstanding success in identifying objects in still images, whether as face recognition, texture classification, or even the recognition of every-day objects in cluttered environments. However these methods typically do not generalize well to video, where our proposed research focuses on two challenges:
The phenomenon of adversarial examples poses a threat to the deployment of the deep neural networks (DNNs) in safety and security sensitive domains. A great progress has been made in this area and different approaches have offered some levels of certified robustness against adversarial examples. However, there are still two main problems remaining for having robust deep neural network models; first, the level of the robustness is not very effective yet, and the second problem is that the current robust training algorithms are computationally very expensive with very high training times. This specially makes them impractical for the real-world problems with large sizes of training data.